

Table of Contents
Structured Data RAG is the missing piece when classic retrieval-augmented generation starts to wobble. Standard RAG leans on embeddings and vector databases to chase semantic similarity; it’s brilliant for open-ended exploration, but it can blur nuance, miss strict constraints, and make provenance hard to audit. If your AI project requires deterministic answers, traceability, and enterprise-grade precision, you need a Structured Data RAG—what many teams call FAST-RAG: Fast, Accurate, Structured Trieval for RAG.
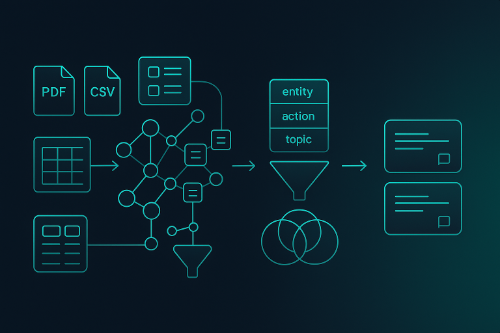
Below, we’ll turn the philosophy into an actionable build plan: ingestion, layout-aware parsing, triple extraction, ontology/indices, a symbolic query layer, and a hybrid fallback that only uses embeddings when logic yields low confidence. You’ll get a clean Python example with CSV + Pandas showing how to stand up a “no-vector-db” FAST-RAG quickly, plus practical guardrails for reliability and SEO-friendly insights your readers will love to bookmark.
WHAT MAKES STRUCTURED DATA RAG DIFFERENT (AND WHY “RAG IS NOT ENOUGH”)
Structured Data RAG replaces “vibes” with logic:
- Similarity-first RAG (vibes): great for “find me related passages,” but may pull near-misses and struggle with multi-constraint questions (e.g., approve + Alice + Q4 initiative + Acme Corp).
- Structured Data RAG (logic): you extract facts—entities, actions, attributes, relationships—then index them for symbolic search. The query becomes an AND/OR/NOT over entity/action/topic/property sets, yielding deterministic intersections and tight provenance.
Result: FAST-RAG narrows to exactly what you asked for, with verifiable traceability.
THE FAST-RAG PIPELINE: FROM RAW DATA TO RELIABLE ANSWERS
1) INTELLIGENT INGESTION & LAYOUT-AWARE CHUNKING
Treat every source (PDF, DOCX, HTML, Markdown, CSV) as a hierarchy. Split on semantic boundaries (titles, paragraphs, tables, lists, footnotes). Never slice a table or clause mid-row; preserve the document’s logic to protect meaning.
2) HIGH-FIDELITY FACT EXTRACTION (TRIPLES & ATTRIBUTES)
Translate natural language into structured triples and properties:
- Entities (who/what): Alice, Acme Corp, Contract-17
- Actions/Events (did what): approved, reviewed, initiated
- Attributes (details): approval_date, owner, budget
Store canonical forms (normalize names/dates/IDs) to prevent duplication.
3) ONTOLOGY & NORMALIZATION
Define categories and relationships your domain cares about: Person → approved → Contract, Contract → belongs_to → Project, Project → phase → Q4. Map synonyms and aliases (e.g., A. Kumar ≈ Anil Kumar). Good ontology = good queries.
4) MULTI-INDEX CONSTRUCTION FOR SYMBOLIC SEARCH
Build fast inverted indexes (sets) keyed by:
- Entity Index (e.g., Alice → {doc, chunk, row})
- Action Index (approved)
- Topic/Hierarchy Index (Finance > Budgeting > Q4)
- Property Index (approval_date: 2024-10-26)
- (Optional) Full-text Index for fallback and snippet display
5) QUERY TRANSLATION → STRUCTURED SEARCH
User asks: “Show contracts approved by Alice at Acme for Q4.”
Your Query Translator turns that into a symbolic filter:entity=Alice AND entity=Acme Corp AND action=approved AND topic=Q4.
6) SET ALGEBRA OVER INDICES
Compute intersections of matching sets. The output is a small, high-precision candidate set guaranteed to contain the logical combination requested.
7) HYBRID FALLBACK FOR AMBIGUITY
If the structured pass yields low confidence, fall back to dense embeddings or full-text semantic as a secondary path. This hybrid keeps precision while staying graceful for vague questions.
8) TRACEABLE ANSWERS
The final LLM sees only the vetted chunks/rows and is instructed to cite sources (doc/Page/Row ID). You can log every hop: what filters matched, which sets intersected, and why each row was included.
WHEN TO CHOOSE STRUCTURED DATA RAG OVER CLASSIC RAG
- Compliance & audit: finance, healthcare, legal, policy—where every answer must be provable.
- Operational analytics: approvals, incidents, SLAs, change logs—where AND/OR/NOT facts matter more than fuzzy similarity.
- Master data questions: “Which vendor contracts with clause X, approved by Y, between these dates?”
- High-risk workflows: anything tied to money, safety, or regulation.
For general brainstorming, classic RAG still shines. For deterministic questions, Structured Data RAG is the right tool.
PRACTICAL BUILD: CSV-FIRST FAST-RAG (NO VECTOR DATABASE REQUIRED)
Below is a compact Python sketch that demonstrates the core mechanics without embeddings: load CSV, normalize entities/dates, build entity/action/topic indexes, translate a natural query into a symbolic filter, and intersect sets to get precise matches. Expand this into your production stack (knowledge graph, Neo4j/Postgres, background jobs, policies) once the workflow proves value.
# fast_rag_csv.py — Minimal Structured Data RAG (FAST-RAG) with CSV + Pandas
import pandas as pd
from collections import defaultdict
import re
# ---- 1) LOAD & NORMALIZE -----------------------------------------------------
df = pd.read_csv("contracts.csv") # columns: contract_id, party, approver, company, topic, action, approval_date, text
def norm(s):
return re.sub(r"\s+", " ", str(s).strip().lower())
# canonical columns
df["party_n"] = df["party"].map(norm)
df["approver_n"] = df["approver"].map(norm)
df["company_n"] = df["company"].map(norm)
df["topic_n"] = df["topic"].map(lambda x: " > ".join([t.strip() for t in str(x).split(">")]).lower())
df["action_n"] = df["action"].map(norm)
df["date_n"] = pd.to_datetime(df["approval_date"], errors="coerce")
# ---- 2) BUILD INVERTED INDEXES ----------------------------------------------
idx_entity = defaultdict(set) # entities: people/companies/parties
idx_action = defaultdict(set)
idx_topic = defaultdict(set)
idx_property = defaultdict(set) # e.g., year or other attributes
for i, row in df.iterrows():
rid = i # row id
for ent in {row["party_n"], row["approver_n"], row["company_n"]}:
idx_entity[ent].add(rid)
idx_action[row["action_n"]].add(rid)
idx_topic[row["topic_n"]].add(rid)
# example property index: by year
if pd.notnull(row["date_n"]):
idx_property[("year", row["date_n"].year)].add(rid)
# ---- 3) QUERY TRANSLATOR (NAIVE) --------------------------------------------
def to_structured(query: str):
"""
Turn a natural question into a structured filter.
Example: 'contracts approved by Alice for Acme in Q4 2024'
"""
q = query.lower()
clauses = []
# simplistic extraction; replace with a proper parser/LLM in production
m_approver = re.search(r"approved by ([a-z\s]+?)\b(for|in|during|$)", q)
if m_approver:
clauses.append(("entity", norm(m_approver.group(1))))
m_company = re.search(r"for ([a-z0-9\s\.-]+?)( in| during|$)", q)
if m_company:
clauses.append(("entity", norm(m_company.group(1))))
# topic detection
if "q4" in q:
clauses.append(("topic", "finance > budgeting > q4"))
# action assumption
clauses.append(("action", "approved"))
# year
m_year = re.search(r"(20\d{2})", q)
if m_year:
clauses.append(("year", int(m_year.group(1))))
return clauses
# ---- 4) SYMBOLIC SEARCH (SET INTERSECTIONS) ----------------------------------
def symbolic_search(query: str):
clauses = to_structured(query)
candidate_sets = []
for typ, val in clauses:
if typ == "entity":
candidate_sets.append(idx_entity.get(val, set()))
elif typ == "action":
candidate_sets.append(idx_action.get(val, set()))
elif typ == "topic":
candidate_sets.append(idx_topic.get(val, set()))
elif typ == "year":
candidate_sets.append(idx_property.get(("year", val), set()))
if not candidate_sets:
return pd.DataFrame(columns=df.columns)
# AND over all clauses
matched = set.intersection(*candidate_sets) if candidate_sets else set()
return df.loc[sorted(matched), :]
# ---- 5) TRY IT ---------------------------------------------------------------
if __name__ == "__main__":
q = "Show contracts approved by Alice for Acme Corp in Q4 2024"
res = symbolic_search(q)
print(res[["contract_id","approver","company","topic","action","approval_date"]])How to extend this into a production-ready FAST-RAG:
- Replace
to_structured()with a Query Translator powered by a small LLM or rules that map entities/actions/topics/dates robustly. - Promote the indexes to a knowledge graph (Neo4j) or relational schema (Postgres + JSONB).
- Add provenance logs: for every hit, store doc ID, page/row, hash.
- Implement a confidence policy: if few results or low certainty → trigger a semantic fallback (an embedding search across text).
- Add a final answer synthesizer that only uses the retrieved snippets and cites them.
ONTOLOGY & INDEX DESIGN: THE SECRET SAUCE OF STRUCTURED DATA RAG
- Entities: people, organizations, assets, document IDs.
- Actions: verbs that matter (approved, signed, shipped, escalated).
- Attributes: dates, amounts, owners, versions, statuses.
- Topics: a hierarchy (e.g., Finance > Budgeting > Q4).
- Properties: arbitrary key-values to slice results (region, product line, severity).
Design tip: start small with a minimum viable ontology. Add relationships as questions emerge in production. Over-engineering the schema up-front slows learning.
WHY “RAG IS NOT ENOUGH” (AND WHEN TO GO HYBRID)
- Strict filters: “All contracts approved by Alice at Acme for Q4” isn’t a “similarity” question; it’s a logic question.
- Compliance: auditors want deterministic filters and citations.
- Disambiguation: “A. Kumar” vs. “Anil Kumar” → require canonicalization.
- Hybrid moment: if a user asks “What are the main risks?” your symbolic sets may be sparse. That’s ok. Trigger the fallback path: semantic similarity to pull context, then label the answer as “best-effort exploratory.”
KPIS, GUARDRAILS, AND ROLLOUT PLAN (FOR ENTERPRISE & STARTUPS)
- Precision@K / Recall@K on known truth sets
- Provenance completeness (does every answer cite rows?)
- Time-to-first-answer and TTFA under load
- Update latency (time from new file → index ready)
- Policy violations (PII leaks, unauthorized joins)
Guardrails: allowlists/denylists for actions, per-user row-level permissions, lineage logging, PII masking, canary rollouts, and automatic regression checks every release.
Rollout plan: pilot one painful workflow → instrument KPIs → iterate ontology → add hybrid fallback only where needed → socialize traceable wins to leadership.
TOOLING YOU MAY USE (MINIMAL LINKS)
- OpenAI (LLM planning/extraction/query translation) — use small structured prompts for stable outputs.
- NVIDIA API Catalog (model variety & deployment choices) — a good place to browse specialized model options.
(Keep external links sparse. If you include any, limit to one doc link like the OpenAI developer docs and one catalog link to NVIDIA—don’t over-link sections.)
FAQ — STRUCTURED DATA RAG / FAST-RAG
Is Structured Data RAG harder than classic RAG?
Yes—because you’re engineering meaning: schema, indexes, provenance. But once it’s running, your team gets repeatable, auditable answers.
Do I need a vector database at all?
Not for the primary path. FAST-RAG can be embedding-free. Keep a semantic fallback only for ambiguous questions.
Where does this shine?
Contracts, compliance, finance ops, healthcare records, policy corpora, customer case analytics—anywhere logic beats vibes.
How do I keep it fresh?
Automate ingestion; re-index deltas; run daily/weekly evals; watch drift in names, formats, and ontologies.
TL;DR — WHY YOUR NEXT AI PROJECT NEEDS STRUCTURED DATA RAG
- RAG is not enough when the stakes demand logic, traceability, and determinism.
- Structured Data RAG (FAST-RAG) gives you symbolic search over clean indexes with hybrid fallback only when necessary.
- Start with CSV + Pandas, ship wins, then grow into knowledge graphs, policies, and governed pipelines.
Recommended External Resources
- OpenAI Developer Docs — for stable JSON prompts & extraction patterns.
- NVIDIA API Catalog — to explore model deployment options.
FINAL CTA
If this Structured Data RAG playbook helped, save it, share it, and try the CSV example today. When you’re ready, I can expand this into a production-grade repo (planner, extraction prompts, ontology schema, indexes, hybrid fallback, citations, and evals) tailored to Tech Niche Pro.



")



: The Essential Playbook for Smarter Coding")
")


")




 — What Comes After AI Agents and Agentic AI?")

")

{kind=link}