

Stop guessing and start building RAG systems that actually retrieve the right context.
Table of Contents
When people build their first RAG system, the logic seems simple.
Split the documents.
Create embeddings.
Search similar chunks.
Send them to the model.
Get an answer.
It sounds clean.
It looks smart.
And in a small demo, it often works well enough to impress people.
Then real users show up.
They ask vague questions.
They use messy wording.
They ask about things described in different terms across different documents.
They expect correct answers every single time.
That is usually the moment the illusion breaks.
Suddenly, the system starts pulling irrelevant chunks. It misses obvious answers. It sounds confident while being wrong. And the team blames the LLM.
But the LLM is often not the real problem.
The real problem is what happened before the answer was generated.
The system retrieved the wrong context.
That is the part many teams underestimate.
A weak retrieval layer can make even a strong model look unreliable.
A strong retrieval layer can make an ordinary setup feel dramatically better.
That is why this matters so much.
This article will walk through 10 practical RAG strategies in plain language, with cleaner code, simple examples, and a realistic roadmap you can actually use.
If your RAG system keeps missing the mark, read this all the way through.
Because one of these fixes may save you weeks of rebuilding the wrong thing.
And if this article helps, clap for it and share it with someone still blaming the model.
Why most RAG systems feel smart in demos but fail in real life
A demo is easy to control.
You know the documents.
You know the expected question.
You know the wording.
You know what “good” looks like.
Production is different.
Users ask:
- “What’s the policy for refunds?”
- “How does onboarding work for enterprise clients?”
- “What changed in Q2?”
- “Can I use this with EU medical data?”
Those questions can be short, incomplete, broad, or badly phrased.
A basic RAG system does not “understand” that gap very well.
It only tries to find nearby text in embedding space and hope that is enough.
Sometimes it is.
Often it is not.
That is why so many RAG systems feel magical in testing and disappointing in production.
The model can only be as grounded as the context you retrieve.
That is the whole game.
What actually breaks in a weak retrieval strategy
Before we jump into fixes, let’s make the pain clear.
Here is what usually goes wrong.
1. Chunking breaks meaning
A sentence or idea gets split in half. One chunk contains the beginning. Another contains the ending. Neither chunk is strong enough on its own.
2. Similarity is not the same as relevance
A chunk may look “close” to the query mathematically but still fail to answer the question.
3. Users do not ask perfect questions
A short query like “pricing rules” may need expansion before retrieval has any chance of finding the right material.
4. Some answers need more context than a tiny chunk can provide
A paragraph alone may not be enough. Sometimes the model needs the whole section or full document.
5. Not every question should use the same retrieval path
Some questions need semantic search. Some need keyword matching. Some need structured data. Some need relationship-aware retrieval.
That is why “search top 5 chunks and pray” is not a strategy.
It is a starting point.
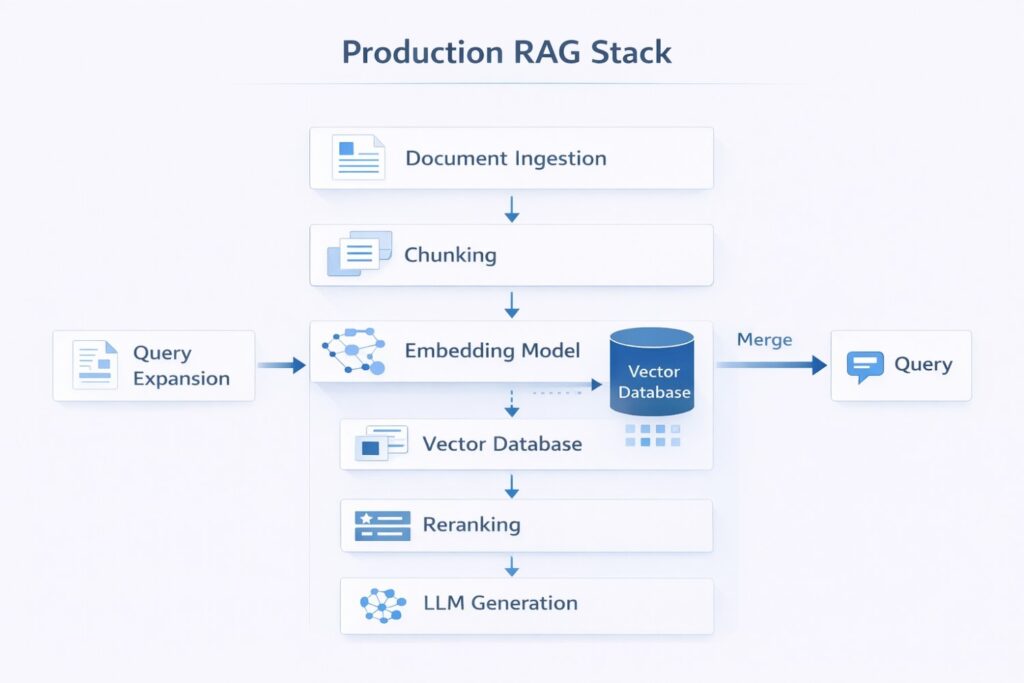
The 10 RAG strategies that make the biggest difference
1) Context-aware chunking: stop slicing documents blindly
This is the first fix most teams should make.

A lot of systems still split documents using fixed character counts or raw token limits. That is easy to implement, but it often breaks meaning.
Imagine this sentence gets cut:
“The company approved the refund after verifying the original enterprise contract terms.”
If the split happens in the middle, one chunk may contain “approved the refund,” and another may contain “enterprise contract terms.”
Now both chunks are weaker.
Context-aware chunking tries to keep related ideas together. It uses headings, paragraphs, sections, and semantic boundaries.
Why this helps:
- better chunk meaning
- less broken context
- cleaner retrieval results
Use this when:
- almost always
- especially for manuals, policies, reports, and long articles
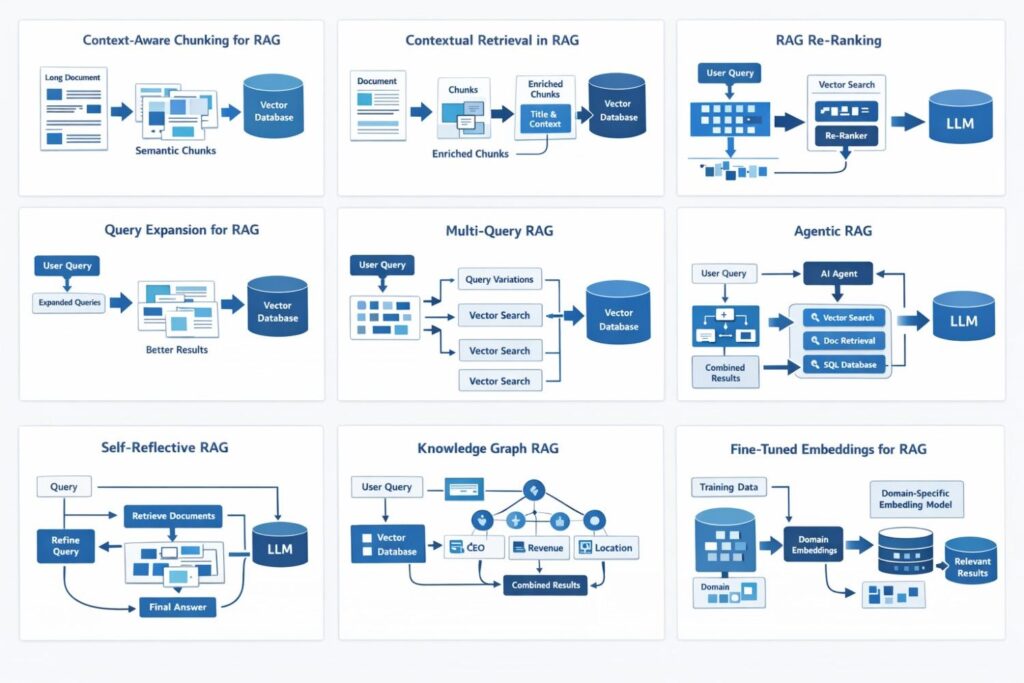
2) Contextual retrieval: make each chunk understandable on its own
A raw chunk often lacks identity.
For example:
“Revenue grew 40%.”
That sounds useful, but useful for what? Which company? Which quarter? Which report?
Contextual retrieval solves this by adding document-level context to the chunk during ingestion.
So instead of storing just:
“Revenue grew 40%.”
You store something more like:
“This section from ACME’s Q2 financial update explains the company’s quarterly revenue growth and margin improvement. Revenue grew 40%.”
Now the chunk is much more self-contained.
Why this helps:
- improves clarity
- makes retrieval stronger
- reduces ambiguity
Use this when:
- accuracy matters a lot
- the documents contain financial, legal, medical, or technical language
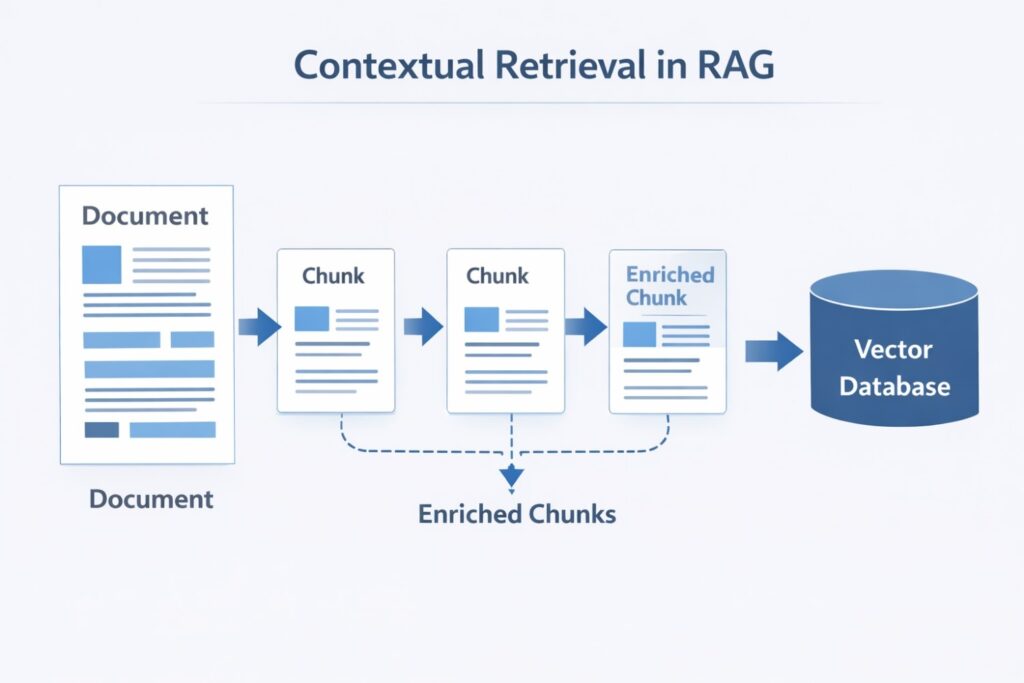
3) Re-ranking: stop trusting the first retrieval result
This is one of the highest-value upgrades in all of RAG.
A vector database may return the “closest” chunks first. But closest is not always best.
Re-ranking adds a second step.
First, you retrieve maybe 20 candidate chunks.
Then, a reranker scores those candidates more carefully against the query.
Then, you keep only the best few.
That simple two-step process often improves precision a lot.
Why this helps:
- removes weak matches
- surfaces more relevant chunks
- improves answer grounding
Use this when:
- wrong answers are costly
- you want a major quality jump without redesigning everything
If you improve only one thing this week, re-ranking is a very strong candidate.
4) Query expansion: help the system understand short questions
Users are lazy.
That is not an insult. It is just reality.

They ask:
- “What is RAG?”
- “refund policy?”
- “healthcare compliance?”
- “deploy model?”
Those are not rich search queries.
Query expansion turns a short question into a more complete one before retrieval happens.
Example:
“refund policy?”
becomes something closer to:
“What is the refund policy, including eligibility, deadlines, payment conditions, and any exceptions for enterprise or annual plans?”
Now retrieval has far more signal to work with.
Why this helps:
- better recall
- better search quality
- fewer misses from vague wording
Use this when:
- users ask short or messy questions
- your system is chat-based
5) Multi-query retrieval: search from more than one angle
Sometimes one phrasing misses what another phrasing finds.
That is why multi-query RAG works.
Instead of sending only one version of the question, the system generates several variations and searches with all of them.
Example:
- “How do I deploy ML models?”
- “How can machine learning models be deployed to production?”
- “Best practices for serving trained models in production”
- “Options for model deployment infrastructure”
Then the results are merged and deduplicated.
Why this helps:
- improves recall
- captures different wording styles
- works well for broad questions
Use this when:
- your documents use varied terminology
- user intent can be expressed in many ways
6) Agentic retrieval: let the system choose the right tool
Some questions are simple. Some are not.
A user may ask:
- “What is the refund policy?”
- “Show me the full contract clause.”
- “What is our churn rate this quarter?”
- “Who approved this compliance change?”
Those should not all use the exact same retrieval path.
Agentic retrieval gives the system multiple tools, such as:
- chunk search
- full-document retrieval
- SQL query access
- keyword search
- graph search
Then the agent decides which tool or combination of tools fits the question best.
Why this helps:
- more flexibility
- better fit for complex environments
- supports documents, databases, and structured systems together
Use this when:
- your data is spread across multiple systems
- your questions vary a lot in type
7) Self-reflective RAG: check the results before trusting them
A basic system accepts whatever it retrieved and moves on.
A smarter system asks:
“Are these results actually good enough?”
That is the idea behind self-reflective RAG.
The system retrieves results, evaluates their relevance, and, if the quality looks poor, it refines the query and tries again.
This adds cost and latency, but it can rescue difficult searches.
Why this helps:
- catches bad first attempts
- improves hard queries
- reduces blind trust in low-quality retrieval
Use this when:
- accuracy matters more than speed
- your users ask high-stakes questions
8) Hierarchical retrieval: search small, return big
Small chunks are good for matching specific phrases.
Large chunks are better for preserving meaning.
Hierarchical RAG tries to get both benefits.
The system stores:
- small child chunks for precise matching
- larger parent chunks for broader context
It searches the child chunks, then returns the parent section to the model.
That gives you precision and context together.
Why this helps:
- reduces shallow answers
- avoids missing larger meaning
- works well on structured documents
Use this when:
- your documents have clear sections
- context often lives above the chunk level
9) Knowledge graph retrieval: capture relationships, not just text similarity
Sometimes similarity search is not enough.
If the query is:
- “Who leads ACME and what changed in Q2?”
- “Which products depend on service X?”
- “Which regulation applies to this medical device?”
You may need relationships, not just matching text.
Knowledge graph retrieval helps the system understand links between entities:
- company → CEO
- company → revenue
- contract → clause
- drug → interaction
- product → dependency
Why this helps:
- stronger reasoning over connected data
- better support for entity-rich questions
- less dependence on loose text similarity alone
Use this when:
- relationships are central to the problem
- your domain has linked entities
10) Fine-tuned embeddings: teach the system your language
Generic embeddings are useful, but they do not always understand specialized language well.
In medical, legal, financial, or technical domains, terms often have very specific meanings.
Fine-tuned embeddings help the system learn what matters in your domain.
That means better retrieval for:
- jargon
- acronyms
- domain-specific phrasing
- nuanced terminology
Why this helps:
- better domain accuracy
- stronger retrieval for specialist content
- more useful results from smaller models
Use this when:
- you work in a specialized field
- generic embeddings keep missing obvious domain matches
The best strategy combinations for different use cases
You do not need all 10 strategies at once.
That would be expensive, hard to debug, and probably unnecessary.
Here are three smarter combinations.
Best overall stack for most teams
- context-aware chunking
- query expansion
- re-ranking
- full-document fallback
This is practical, strong, and easy to justify.
Best for high-accuracy systems
- contextual retrieval
- multi-query search
- re-ranking
- self-reflection
Use this when bad answers are expensive.
Best for specialized domains
- fine-tuned embeddings
- contextual retrieval
- knowledge graph retrieval
- re-ranking
Use this when your domain language and relationships matter a lot.
Cleaner code: from naive RAG to production-ready retrieval
Below is a much better version of the original concept. It is still simple, but it removes the biggest mistakes.
Naive version
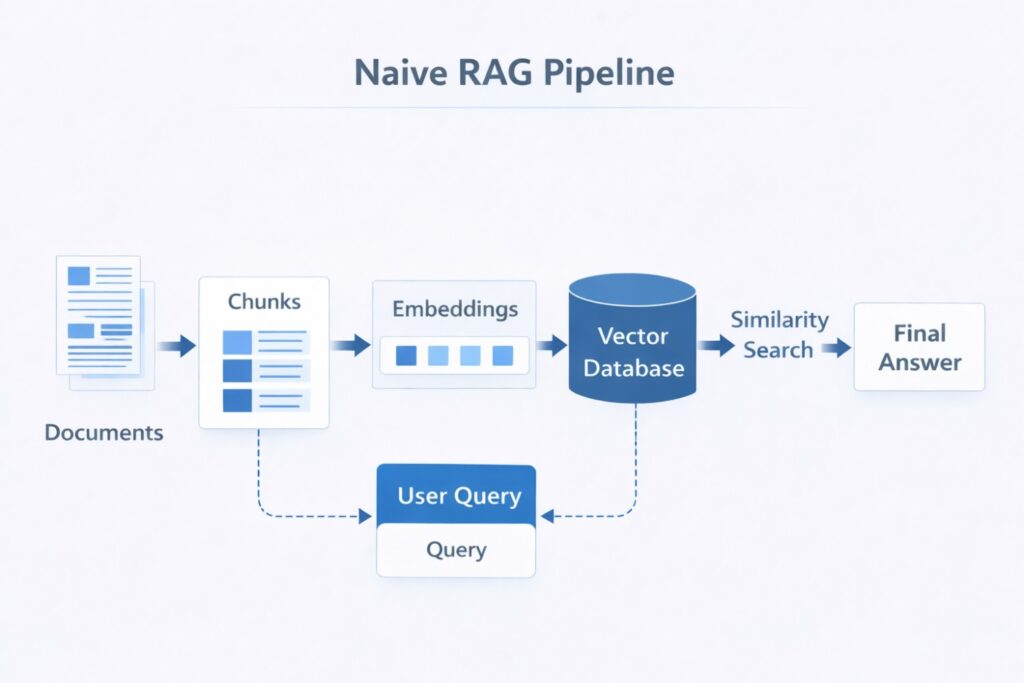
def naive_rag(query: str) -> str:
# Convert the user question into an embedding vector
query_embedding = embed(query) # Retrieve the top 5 nearest chunks
chunks = vector_db.search(query_embedding, top_k=5) # Join the retrieved text into one context block
context = "\n".join(chunks) # Ask the model to answer using the retrieved context
return llm.generate(
f"Context:\n{context}\n\nQuestion:\n{query}"
)Why this fails:
- no query improvement
- no reranking
- no source handling
- no fallback logic
- no protection against irrelevant context
Improved version
from typing import List, Dict, Any
from sentence_transformers import CrossEncoder
class ProductionReadyRAG:
"""
A beginner-friendly RAG pipeline with better retrieval quality.
What this class improves:
1. Expands short queries before search
2. Retrieves more candidates first
3. Re-ranks candidates using a stronger relevance model
4. Builds cleaner context for the LLM
5. Handles empty retrieval safely
"""
def __init__(self, vector_db, embedder, llm):
self.vector_db = vector_db
self.embedder = embedder
self.llm = llm
# Cross-encoder reranker:
# much better at scoring "Does this chunk answer the query?"
self.reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
def expand_query(self, query: str) -> str:
"""
Expand very short questions so retrieval has more context.
Replace this rule-based version with an LLM call in production if needed.
"""
cleaned = query.strip()
if len(cleaned.split()) >= 7:
return cleaned
return (
f"{cleaned}. Include related definitions, conditions, examples, "
f"and important details that help answer this question accurately."
)
def retrieve_candidates(self, query: str, top_k: int = 20) -> List[Dict[str, Any]]:
"""
Retrieve a wider candidate set first.
We do not trust the first 5 matches blindly.
"""
query_embedding = self.embedder.embed_query(query)
return self.vector_db.search(query_embedding, top_k=top_k)
def rerank_candidates(
self,
original_query: str,
candidates: List[Dict[str, Any]],
final_k: int = 5
) -> List[Dict[str, Any]]:
"""
Use a reranker to sort chunks by actual relevance.
"""
if not candidates:
return []
pairs = []
for item in candidates:
pairs.append([original_query, item["content"]])
scores = self.reranker.predict(pairs)
scored = []
for item, score in zip(candidates, scores):
scored.append({
**item,
"rerank_score": float(score)
})
scored.sort(key=lambda x: x["rerank_score"], reverse=True)
return scored[:final_k]
def build_context(self, chunks: List[Dict[str, Any]]) -> str:
"""
Format context with simple source labels.
This helps both debugging and answer grounding.
"""
parts = []
for idx, chunk in enumerate(chunks, start=1):
source = chunk.get("source", f"Document {idx}")
content = chunk.get("content", "").strip()
parts.append(f"[Source: {source}]\n{content}")
return "\n\n".join(parts)
def answer(self, query: str) -> str:
"""
Full retrieval pipeline.
"""
expanded_query = self.expand_query(query)
candidates = self.retrieve_candidates(expanded_query, top_k=20)
best_chunks = self.rerank_candidates(query, candidates, final_k=5)
if not best_chunks:
return "I could not find enough relevant context to answer that question."
context = self.build_context(best_chunks)
prompt = f"""
You are a helpful assistant.
Answer the user's question using only the retrieved context below.
If the context is incomplete, say so clearly.
Do not invent facts.
User Question:
{query}
Retrieved Context:
{context}
Answer:
""".strip()
return self.llm.generate(prompt)Why this version is better
It improves the retrieval strategy in four important ways:
- It expands weak user queries
- It retrieves broadly before filtering
- It re-ranks for precision
- It builds cleaner grounded context for the final answer
That is already a major upgrade without making the system too hard to understand.
Common mistakes that quietly ruin RAG accuracy
Mistake 1: Using fixed chunk sizes everywhere
This is fast, but often careless.
Mistake 2: Skipping re-ranking
This leaves too much trust in raw similarity scores.
Mistake 3: Treating vague user queries as “good enough”
They usually are not.
Mistake 4: Using one retrieval path for every question
That limits the system badly.
Mistake 5: Overengineering too early
You do not need every advanced idea on day one.
Mistake 6: Changing the LLM before fixing retrieval
This is one of the most common wasted moves in RAG work.
A better model cannot save bad context.
That line alone explains a huge amount of failure.
A simple roadmap to improve your RAG system
If you want a clean plan, use this order.
Step 1: Fix chunking
Move away from blind chunk splits.
Step 2: Add re-ranking
This is often the biggest quick win.
Step 3: Expand short queries
Especially important for chat-based systems.
Step 4: Add contextual retrieval
Great for high-value documents.
Step 5: Add multi-query or agentic routing
Do this once your basic retrieval is stable.
Step 6: Add domain-specific upgrades
Fine-tuned embeddings or knowledge graphs only when the use case truly needs them.
That is how you scale smart.
Not by stacking fancy techniques all at once.
But by fixing the most painful failure modes first.
Final thoughts
Your RAG system may not be broken.
It may simply be retrieving the wrong context.
That sounds like a small distinction.
It is not.
It changes where you look, what you fix, and how fast the system improves.
Once you understand that, you stop obsessing over prompts and model swaps.
You start focusing on the layer that decides whether the model ever gets a fair chance to succeed.
That is the real shift.
And that is why some RAG systems feel unreliable while others feel surprisingly sharp.
They are not always using better models.
They are using better retrieval strategy.
If this article helped you see your RAG stack more clearly, clap for it, share it, and send it to someone who is still trying to solve a retrieval problem with a model change.
Because that mistake is more common than people think.
And fixing it is where the real progress begins.
12. FAQ Section
1. What is the biggest reason RAG systems fail?
The biggest reason is weak retrieval. If the system brings the wrong context to the model, the final answer will often be wrong too.
2. Which RAG strategy should I implement first?
Start with context-aware chunking and re-ranking. For most teams, that is the fastest path to better retrieval quality.
3. Why is re-ranking important for RAG accuracy?
Re-ranking helps choose the most relevant results from a larger candidate set. It improves precision and reduces noisy context.
4. Does query expansion really help a production RAG system?
Yes. It is especially useful when users ask short, vague, or incomplete questions. It gives retrieval more signal to work with.
5. What is the best retrieval strategy for production RAG?
A strong default stack is context-aware chunking, query expansion, vector retrieval, and re-ranking, with a full-document fallback when needed.
6. When should I use knowledge graphs in RAG?
Use them when relationships between people, products, events, regulations, or entities are central to the questions users ask.
7. Are fine-tuned embeddings worth it?
Yes, in specialized domains like legal, medical, financial, or technical systems where generic embeddings often miss important terminology.
Bonus resources:
— YouTube ▶️ https://youtu.be/GHy73SBxFLs
— Book ▶️ https://www.amazon.com/dp/B0CKGWZ8JT
— More Reads ▶️ https://www.technichepro.com
Let’s Connect
Email: krtarunsingh@gmail.com
LinkedIn: Tarun Singh
GitHub: github.com/krtarunsingh
Buy Me a Coffee: https://buymeacoffee.com/krtarunsingh
YouTube: @tarunaihacks
👉 If you found value here, like, share, and leave a comment —i t helps more devs discover practical guides like this.


")

")
: Tools, Memory, Planning — In One Clean File")



")



")


: FAST-RAG Without Vectors")



{kind=link}